
At its Cloud Information Summit, Google at the moment introduced the preview launch of BigLake, a brand new data lake storage engine that makes it simpler for enterprises to investigate the info of their knowledge warehouses and knowledge lakes.
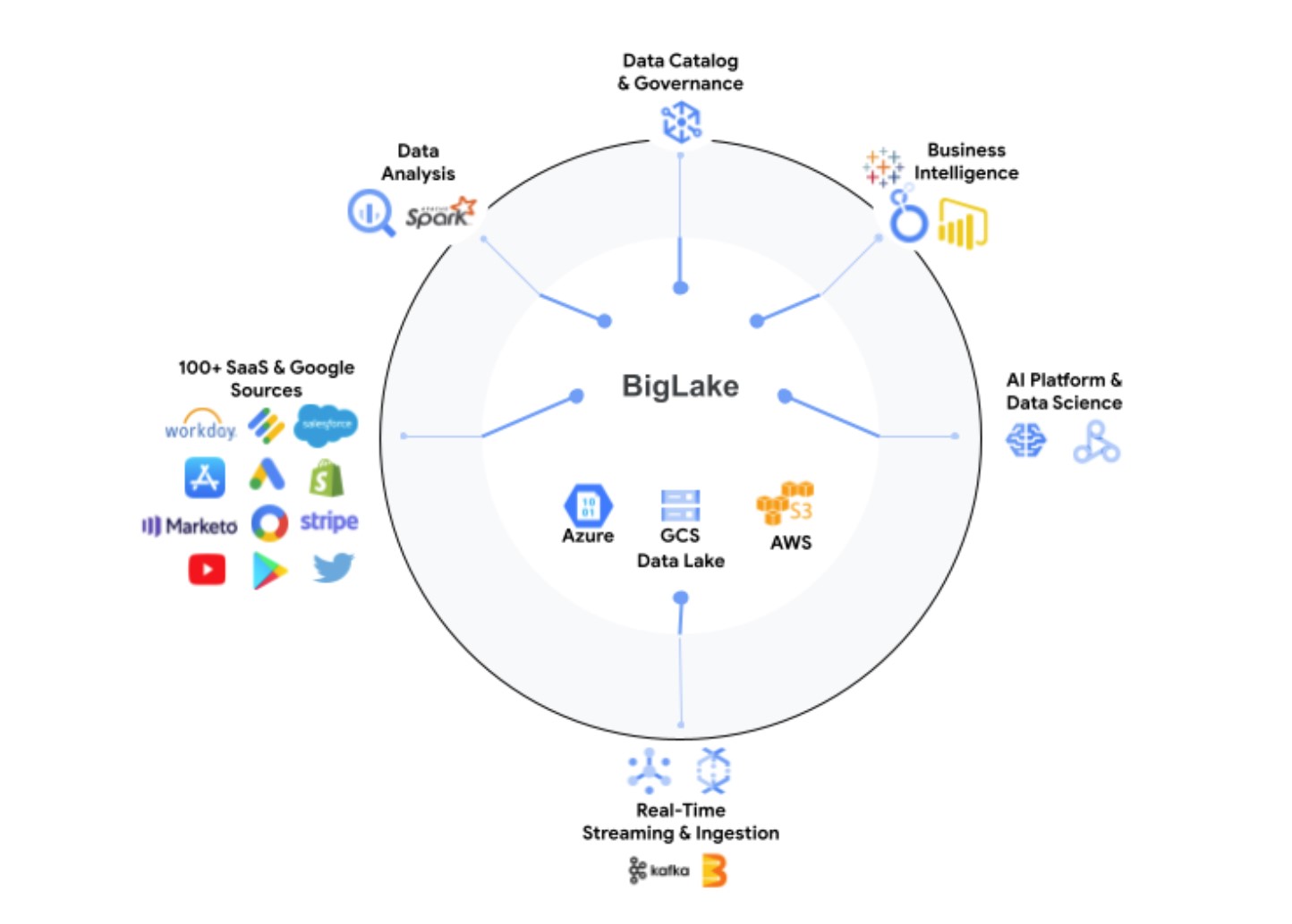
The thought right here, at its core, is to take Google’s expertise with working and managing its BigQuery knowledge warehouse and prolong it to knowledge lakes on Google Cloud Storage, combining the most effective of information lakes and warehouses right into a single service that abstracts away the underlying storage codecs and techniques.
This knowledge, it’s value noting, may sit in BigQuery or dwell on AWS S3 and Azure Data Lake Storage Gen2, too. By means of BigLake, builders will get entry to 1 uniform storage engine and the flexibility to question the underlying knowledge shops by way of a single system with out the necessity to transfer or duplicate knowledge.
“Managing knowledge throughout disparate lakes and warehouses creates silos and will increase danger and price, particularly when knowledge must be moved,” explains Gerrit Kazmaier, VP and GM of Databases, Information Analytics and Enterprise Intelligence at Google Cloud, notes in at the moment’s announcement. “BigLake permits firms to unify their knowledge warehouses and lakes to investigate knowledge with out worrying concerning the underlying storage format or system, which eliminates the necessity to duplicate or transfer knowledge from a supply and reduces price and inefficiencies.”
Picture Credit: Google
Utilizing coverage tags, BigLake permits admins to configure their safety insurance policies on the desk, row and column degree. This contains knowledge saved in Google Cloud Storage, in addition to the 2 supported third-party techniques, the place BigQuery Omni, Google’s multi-cloud analytics service, allows these safety controls. These safety controls then additionally be certain that solely the correct knowledge flows into instruments like Spark, Presto, Trino and TensorFlow. The service additionally integrates with Google’s Dataplex instrument to offer further knowledge administration capabilities.
Google notes that BigLake will present fine-grained entry controls and that its API will span Google Cloud, in addition to file codecs just like the open column-oriented Apache Parquet and open-source processing engines like Apache Spark.
Picture Credit: Google
“The quantity of useful knowledge that organizations need to handle and analyze is rising at an unbelievable price,” Google Cloud software program engineer Justin Levandoski and product supervisor Gaurav Saxena clarify in at the moment’s announcement. “This knowledge is more and more distributed throughout many areas, together with knowledge warehouses, knowledge lakes, and NoSQL shops. As a company’s knowledge will get extra complicated and proliferates throughout disparate knowledge environments, silos emerge, creating elevated danger and price, particularly when that knowledge must be moved. Our clients have made it clear; they need assistance.”
Along with BigLake, Google additionally at the moment introduced that Spanner, its globally distributed SQL database, will quickly get a brand new characteristic referred to as “change streams.” With these, customers can simply monitor any modifications to a database in actual time, be these inserts, updates or deletes. “This ensures clients all the time have entry to the freshest knowledge as they will simply replicate modifications from Spanner to BigQuery for real-time analytics, set off downstream software conduct utilizing Pub/Sub, or retailer modifications in Google Cloud Storage (GCS) for compliance,” explains Kazmaier.
Google Cloud additionally at the moment introduced Vertex AI Workbench, a instrument for managing the whole lifecycle of a knowledge science mission, out of beta and into normal availability, and launched Linked Sheets for Looker, in addition to the flexibility to entry Looker knowledge fashions in its Information Studio BI instrument.

{kind=link}